Improving Outcomes for Diabetes Patients through Data Science
Data
250,000 patients hospitalized with diabetes, 60+ Variables
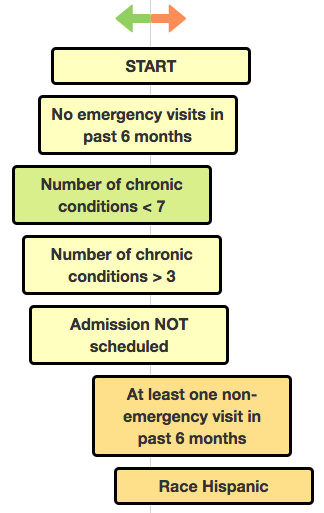
Machine Learning Model
A rules-based decision tree to enable easy interpretation of risk factors
User Experience
Timely insight for hospitals and medical professionals